Introduction
Model Distillation & Compression Tooling refers to software solutions and frameworks that reduce the size, computational requirements, and latency of machine learning models while retaining their predictive accuracy. These tools transform large, resource-intensive models into lighter versions that can run efficiently on edge devices, mobile applications, or cost-sensitive production environments. with the proliferation of LLMs, generative AI, and multimodal models, distillation and compression have become essential. Optimized models allow organizations to deploy AI at scale without excessive compute costs, power consumption, or latency issues.
Real-world use cases include:
- Deploying LLMs on mobile devices or edge hardware.
- Reducing inference costs in cloud-based AI services.
- Accelerating computer vision models for real-time video analysis.
- Compressing models for IoT and embedded systems.
- Ensemble and multi-model deployments requiring efficiency.
What buyers should evaluate:
- Supported frameworks (PyTorch, TensorFlow, ONNX)
- Techniques supported (distillation, pruning, quantization, knowledge transfer)
- Performance and accuracy trade-offs
- Deployment targets (cloud, edge, mobile)
- Automation of compression pipelines
- Integration with MLOps and CI/CD pipelines
- Monitoring and validation tools
- Scalability for large models
- Security and compliance features
- Cost and resource optimization
Best for: AI teams, enterprises, and developers deploying large models in production where efficiency and cost are critical. Industries include SaaS, mobile apps, healthcare, and autonomous systems.
Not ideal for: Small models or experimental projects with minimal resource constraints; direct deployment without compression may suffice.
Key Trends in Model Distillation & Compression Tooling
- Increased adoption of LLM and multimodal model distillation.
- Enhanced quantization and pruning techniques for high-performance inference.
- Automated pipelines for knowledge distillation across model versions.
- Edge-focused model compression for IoT and mobile AI.
- Integration with MLOps pipelines for continuous optimization.
- AI-driven optimization strategies to balance accuracy and efficiency.
- Benchmarking frameworks for performance vs. size trade-offs.
- Open-source and commercial hybrid toolsets for flexibility and enterprise adoption.
- Standardization of evaluation metrics for compressed models.
- Adoption of hardware-aware compression, targeting GPUs, CPUs, and NPUs.
How We Selected These Tools (Methodology)
- Evaluated market adoption and mindshare across AI developer communities.
- Analyzed feature completeness, including support for distillation, quantization, and pruning.
- Assessed reliability and performance in real-world deployments.
- Verified security posture, access controls, and compliance capabilities.
- Examined integration with MLOps pipelines and CI/CD frameworks.
- Considered support for multiple frameworks (PyTorch, TensorFlow, ONNX).
- Reviewed ecosystem support, including documentation, libraries, and community adoption.
- Evaluated scalability and flexibility for cloud and edge deployment.
- Compared cost efficiency and licensing models.
- Ensured 2026+ relevance, especially for large-scale LLMs and multimodal AI.
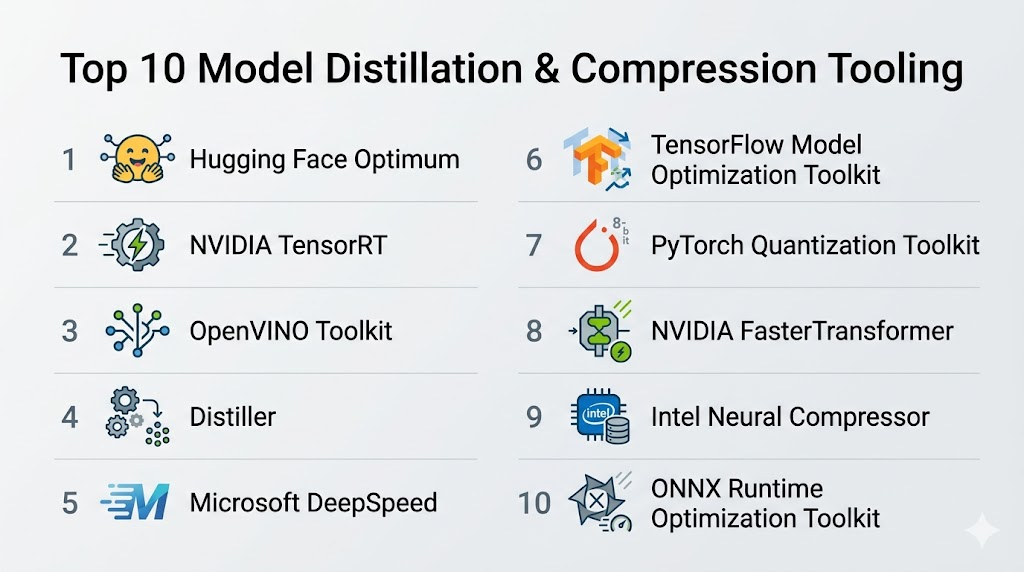
Top 10 Model Distillation & Compression Tooling
1- Hugging Face Optimum
Short description: Optimizes transformers for faster inference and smaller memory footprint. Best for developers working with Hugging Face models.
Key Features
- Supports distillation, quantization, and pruning
- Hardware-aware optimization (CPU, GPU, NPU)
- Integration with Hugging Face Transformers library
- Auto-optimization pipelines
- Benchmarking and validation tools
Pros
- Streamlined for Hugging Face ecosystem
- Improves inference speed and reduces costs
- Open-source and community supported
Cons
- Limited to Transformer-based models
- May require tuning for non-standard hardware
Platforms / Deployment
- Linux, macOS, Windows
- Cloud / Self-hosted / Hybrid
Security & Compliance
- Not publicly stated
Integrations & Ecosystem
- Hugging Face Hub
- Transformers library
- CI/CD and MLOps pipelines
Support & Community
Active developer community, extensive documentation, forums.
2- NVIDIA TensorRT
Short description: High-performance deep learning inference optimizer and runtime. Ideal for GPU-intensive AI workloads.
Key Features
- TensorRT graph optimization
- Precision calibration and quantization
- Support for FP16 and INT8 inference
- GPU acceleration for LLMs and CV models
- Integration with ONNX and PyTorch models
Pros
- Extremely fast GPU inference
- Optimized for NVIDIA hardware
- Supports large-scale production deployments
Cons
- Hardware-specific (NVIDIA GPUs)
- Steeper learning curve for non-NVIDIA users
Platforms / Deployment
- Linux, Docker
- Cloud / Self-hosted / Hybrid
Security & Compliance
- Not publicly stated
Integrations & Ecosystem
- ONNX, PyTorch
- CUDA toolkit
- GPU monitoring and logging
Support & Community
Official NVIDIA support, strong developer forums.
3- OpenVINO Toolkit
Short description: Intel’s toolkit for optimizing models for CPU and VPU inference. Best for edge AI and vision workloads.
Key Features
- Model conversion and optimization
- Pruning and quantization support
- CPU and VPU acceleration
- Benchmarking tools
- Open-source deployment pipelines
Pros
- Hardware-aware optimization for Intel devices
- Lightweight for edge deployments
- Supports multiple frameworks
Cons
- Limited GPU support
- Less suitable for large LLMs
Platforms / Deployment
- Linux, Windows
- Cloud / Self-hosted / Edge
Security & Compliance
- Not publicly stated
Integrations & Ecosystem
- OpenCV, ONNX
- Deployment on edge devices
- CI/CD pipeline integration
Support & Community
Intel documentation, active GitHub community.
4- Distiller (Nervana)
Short description: Open-source Python library for neural network compression. Suitable for research and small-to-mid scale production.
Key Features
- Supports pruning and quantization
- Flexible pipeline for custom compression strategies
- Model accuracy vs size trade-off analysis
- TensorFlow and PyTorch support
- Visualization of compression results
Pros
- Open-source and flexible
- Fine-grained control over compression
- Visualization helps in model evaluation
Cons
- Limited enterprise support
- Smaller community than mainstream frameworks
Platforms / Deployment
- Linux, macOS
- Cloud / Self-hosted / Hybrid
Security & Compliance
- Not publicly stated
Integrations & Ecosystem
- TensorFlow, PyTorch
- CI/CD integration
- Visualization libraries
Support & Community
Open-source community, documentation available.
5- Microsoft DeepSpeed
Short description: Optimization library for deep learning models with memory and speed improvements. Best for large-scale LLMs.
Key Features
- Model parallelism and pipeline optimization
- Mixed precision and quantization support
- Memory-efficient training and inference
- Multi-GPU and distributed support
- Integration with PyTorch
Pros
- Excellent for large-scale LLMs
- Reduces memory and inference cost
- Supports distributed training and inference
Cons
- Complexity for small models
- PyTorch-dependent
Platforms / Deployment
- Linux, Docker
- Cloud / Self-hosted / Hybrid
Security & Compliance
- Not publicly stated
Integrations & Ecosystem
- PyTorch
- Multi-GPU clusters
- CI/CD pipelines
Support & Community
Active GitHub, Microsoft support channels.
6- TensorFlow Model Optimization Toolkit
Short description: TensorFlow’s library for pruning, quantization, and clustering. Ideal for mobile and edge deployments.
Key Features
- Post-training quantization
- Weight pruning and clustering
- TensorFlow Lite conversion
- Model size and latency reduction
- Visualization and metrics
Pros
- Easy integration with TensorFlow workflows
- Optimized for mobile and edge
- Open-source and widely adopted
Cons
- TensorFlow-specific
- Limited support for non-TF frameworks
Platforms / Deployment
- Linux, Windows, macOS
- Cloud / Self-hosted / Hybrid
Security & Compliance
- Not publicly stated
Integrations & Ecosystem
- TensorFlow, TFLite
- Mobile deployment pipelines
- CI/CD integration
Support & Community
TensorFlow docs, active community forums.
7- PyTorch Quantization Toolkit
Short description: Toolkit for quantizing PyTorch models. Best for developers optimizing PyTorch networks for efficiency.
Key Features
- Static and dynamic quantization
- FX graph mode and post-training optimization
- Integration with TorchScript
- Mobile and server deployment
- Performance benchmarking
Pros
- Easy for PyTorch users
- Reduces model size and latency
- Supports mobile and edge devices
Cons
- Limited to PyTorch
- Requires careful tuning for accuracy
Platforms / Deployment
- Linux, macOS, Windows
- Cloud / Self-hosted / Hybrid
Security & Compliance
- Not publicly stated
Integrations & Ecosystem
- PyTorch, TorchScript
- CI/CD pipelines
- Mobile deployment frameworks
Support & Community
PyTorch forums, official docs.
8- NVIDIA FasterTransformer
Short description: Optimized inference library for Transformer models. Ideal for GPU-heavy LLM deployment.
Key Features
- Transformer kernel optimization
- INT8 and FP16 support
- Multi-GPU support
- Integration with TensorRT and PyTorch
- High-throughput inference
Pros
- Extremely fast for large Transformers
- GPU-optimized
- Supports production-grade LLM inference
Cons
- GPU-specific
- Complex setup for multi-GPU clusters
Platforms / Deployment
- Linux, Docker
- Cloud / Self-hosted / Hybrid
Security & Compliance
- Not publicly stated
Integrations & Ecosystem
- TensorRT, PyTorch
- Multi-GPU pipelines
- CI/CD integration
Support & Community
NVIDIA support, developer forums.
9- Intel Neural Compressor
Short description: Framework for quantization, pruning, and accuracy-aware compression. Suitable for CPU and edge optimization.
Key Features
- Post-training quantization
- Pruning and clustering
- Accuracy-aware compression
- Benchmarking and validation tools
- Multi-framework support
Pros
- CPU and edge optimization
- Open-source
- Supports multiple frameworks
Cons
- Limited GPU support
- Smaller community than NVIDIA tools
Platforms / Deployment
- Linux, Windows
- Cloud / Self-hosted / Edge
Security & Compliance
- Not publicly stated
Integrations & Ecosystem
- TensorFlow, PyTorch, ONNX
- CI/CD pipelines
- Edge deployment pipelines
Support & Community
Intel docs and GitHub community.
10- ONNX Runtime Optimization Toolkit
Short description: Toolkit for model optimization across ONNX-compatible models. Ideal for multi-framework deployment.
Key Features
- Quantization and pruning support
- Graph optimization and fusion
- Hardware-aware acceleration
- Multi-framework model compatibility
- Integration with ONNX Runtime
Pros
- Framework-agnostic
- Multi-platform deployment
- Optimizes inference performance
Cons
- Limited to ONNX models
- Requires careful tuning for accuracy
Platforms / Deployment
- Linux, Windows, macOS
- Cloud / Self-hosted / Hybrid
Security & Compliance
- Not publicly stated
Integrations & Ecosystem
- ONNX, PyTorch, TensorFlow
- CI/CD pipelines
- Cloud and edge deployment
Support & Community
Open-source community and official documentation.
Comparison Table (Top 10)
| Tool Name | Best For | Platform(s) Supported | Deployment | Standout Feature | Public Rating |
|---|---|---|---|---|---|
| Hugging Face Optimum | Transformers optimization | Linux, macOS, Windows | Cloud/Self-hosted/Hybrid | Hardware-aware distillation | N/A |
| NVIDIA TensorRT | GPU inference | Linux, Docker | Cloud/Self-hosted/Hybrid | High-throughput GPU optimization | N/A |
| OpenVINO Toolkit | Edge and CPU inference | Linux, Windows | Cloud/Self-hosted/Edge | CPU/VPU acceleration | N/A |
| Distiller | Flexible pruning & quantization | Linux, macOS | Cloud/Self-hosted/Hybrid | Fine-grained control | N/A |
| Microsoft DeepSpeed | LLM optimization | Linux, Docker | Cloud/Self-hosted/Hybrid | Distributed training & inference | N/A |
| TF Model Optimization Toolkit | Mobile & edge | Linux, Windows, macOS | Cloud/Self-hosted/Hybrid | Post-training quantization | N/A |
| PyTorch Quantization Toolkit | PyTorch models | Linux, macOS, Windows | Cloud/Self-hosted/Hybrid | TorchScript integration | N/A |
| NVIDIA FasterTransformer | Transformer inference | Linux, Docker | Cloud/Self-hosted/Hybrid | Optimized GPU kernels | N/A |
| Intel Neural Compressor | CPU & edge | Linux, Windows | Cloud/Self-hosted/Edge | Accuracy-aware compression | N/A |
| ONNX Runtime Optimization Toolkit | Multi-framework | Linux, Windows, macOS | Cloud/Self-hosted/Hybrid | Hardware-aware ONNX optimization | N/A |
Evaluation & Scoring of Model Distillation & Compression Tooling
| Tool Name | Core | Ease | Integrations | Security | Performance | Support | Value | Weighted Total |
|---|---|---|---|---|---|---|---|---|
| Hugging Face Optimum | 9 | 8 | 8 | 6 | 8 | 8 | 8 | 7.9 |
| NVIDIA TensorRT | 10 | 7 | 8 | 6 | 10 | 8 | 8 | 8.6 |
| OpenVINO Toolkit | 8 | 7 | 7 | 6 | 8 | 7 | 8 | 7.5 |
| Distiller | 8 | 8 | 7 | 6 | 7 | 6 | 7 | 7.1 |
| Microsoft DeepSpeed | 9 | 8 | 8 | 6 | 9 | 8 | 8 | 8.1 |
| TF Model Optimization Toolkit | 8 | 8 | 7 | 6 | 7 | 7 | 8 | 7.5 |
| PyTorch Quantization Toolkit | 8 | 8 | 7 | 6 | 7 | 7 | 8 | 7.5 |
| NVIDIA FasterTransformer | 10 | 7 | 8 | 6 | 10 | 8 | 8 | 8.6 |
| Intel Neural Compressor | 8 | 7 | 7 | 6 | 8 | 7 | 7 | 7.4 |
| ONNX Runtime Optimization Toolkit | 8 | 8 | 8 | 6 | 8 | 7 | 8 | 7.7 |
Which Model Distillation & Compression Tool Is Right for You?
Solo / Freelancer
- Distiller, PyTorch Quantization Toolkit, TF Model Optimization for lightweight experiments and local testing.
SMB
- Hugging Face Optimum, Intel Neural Compressor, OpenVINO Toolkit for production-ready edge and cloud deployment.
Mid-Market
- Microsoft DeepSpeed, NVIDIA TensorRT for LLM optimization and GPU-accelerated inference.
Enterprise
- NVIDIA FasterTransformer, Hugging Face Optimum, DeepSpeed for large-scale LLM and multimodal deployments.
Budget vs Premium
- Open-source frameworks reduce costs.
- Managed or enterprise-grade solutions offer better scalability and support.
Feature Depth vs Ease of Use
- Open-source frameworks provide more control and flexibility.
- Managed tools simplify deployment, monitoring, and performance tuning.
Integrations & Scalability
- Platforms with MLOps and CI/CD integration are easier to scale.
- Hardware-aware tools improve efficiency across cloud and edge.
Security & Compliance Needs
- Consider SOC 2, RBAC, and encryption if deploying in regulated industries.
- Managed platforms often simplify compliance adherence.
Frequently Asked Questions (FAQs)
1- What is model distillation and compression tooling?
It reduces the size, memory, and compute requirements of ML models.
Maintains accuracy while improving efficiency.
Enables deployment on edge devices or mobile apps.
Helps scale AI workloads cost-effectively.
2- Why is it important in 2026?
LLMs and multimodal models are increasingly large.
Compressed models reduce latency, memory, and cloud costs.
Supports real-time inference on constrained hardware.
Critical for mobile, IoT, and cloud AI deployments.
3- Do these tools affect model accuracy?
Yes, some accuracy trade-offs may occur.
Modern techniques preserve most predictive performance.
Benchmarking is needed post-compression.
Monitoring ensures acceptable accuracy thresholds.
4- Can they be used with LLMs?
Yes, frameworks like DeepSpeed and FasterTransformer are optimized for LLMs.
Support multi-GPU and distributed inference.
Reduce memory footprint and inference latency.
Compatible with transformer-based architectures.
5- Are these tools open-source or managed?
Many are open-source like Distiller, ONNX Runtime, Optimum.
Enterprise tools include NVIDIA TensorRT and DeepSpeed.
Choice depends on expertise, scale, and budget.
Open-source allows flexibility; managed simplifies deployment.
6- Do they support edge deployment?
Yes, OpenVINO, TF Model Optimization, and Intel Neural Compressor target edge devices.
Optimized for CPUs, VPUs, and mobile hardware.
Enable low-latency and offline inference.
Ideal for IoT and embedded AI applications.
7- Can I integrate these with CI/CD pipelines?
Yes, they provide APIs for automated model compression.
Supports testing and benchmarking in MLOps pipelines.
Reduces manual intervention in model updates.
Enables reproducible deployments across environments.
8- What types of compression are supported?
Pruning, quantization, knowledge distillation, and clustering.
Hardware-aware optimizations for GPU, CPU, or edge.
Framework-specific pipelines like PyTorch and TensorFlow.
Balance between model size and accuracy is configurable.
9- What are common mistakes when using these tools?
Neglecting accuracy validation after compression.
Ignoring hardware constraints or deployment target.
Over-compressing, leading to performance drop.
Failing to integrate with CI/CD or monitoring pipelines.
10- Are these tools suitable for all models?
Mostly effective for large neural networks and LLMs.
Small models may not benefit significantly.
Transformer and convolutional architectures are well-supported.
Evaluate trade-offs based on model type and deployment needs.
Conclusion
Model Distillation & Compression Tooling is critical for optimizing AI model efficiency and scalability.
These frameworks enable deployment on edge devices, mobile platforms, and cloud environments.
Open-source options provide flexibility and cost savings.
Enterprise-grade tools offer performance, support, and hardware-aware optimization.
Selecting the right tool depends on model size, deployment target, and budget.
Integration with MLOps pipelines ensures reproducibility and monitoring.
Techniques include pruning, quantization, clustering, and knowledge distillation.
Benchmarks and evaluation ensure minimal accuracy loss post-compression.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals
I wanted to understand model distillation and compression better, and this content helped me learn how these techniques can make AI models more efficient and easier to deploy.